


Los desarrolladores de modelos de aprendizaje automático (ML) a menudo comienzan con un modelo básico básico que ha sido ampliamente capacitado y se puede aplicar a una variedad de aplicaciones posteriores. Muchos modelos troncales populares en el procesamiento del lenguaje natural, como BERT, T5 y GPT-3 (también conocidos como «modelos de línea de base»), se entrenaron previamente en datos a escala web y ofrecieron capacidades generales multitarea sin disparo, pocos disparos, o transferir el aprendizaje. El entrenamiento previo de modelos troncales para muchas funciones posteriores puede consumir costos de entrenamiento, lo que ayuda a superar las limitaciones de recursos cuando se desarrollan modelos a gran escala en lugar de entrenar modelos individuales demasiado especializados.
El trabajo pionero en el campo de la visión por computadora demostró la capacidad de los modelos de codificador único preentrenados para clasificar imágenes para capturar representaciones visuales generales útiles para diversas aplicaciones finales. Se usaron pares de imagen-texto de spam en toda la Web para entrenar técnicas de codificación de varianza dual (CLIP, ALIGN, Florence) y decodificación generativa (SimVLM). Los modelos de codificación doble son excelentes para clasificar imágenes sin toma, pero son menos adecuados para comprender el lenguaje de visión común. Por otro lado, los métodos del decodificador son buenos para nombrar imágenes y responder preguntas visuales, pero no son tareas de estilo loopback.
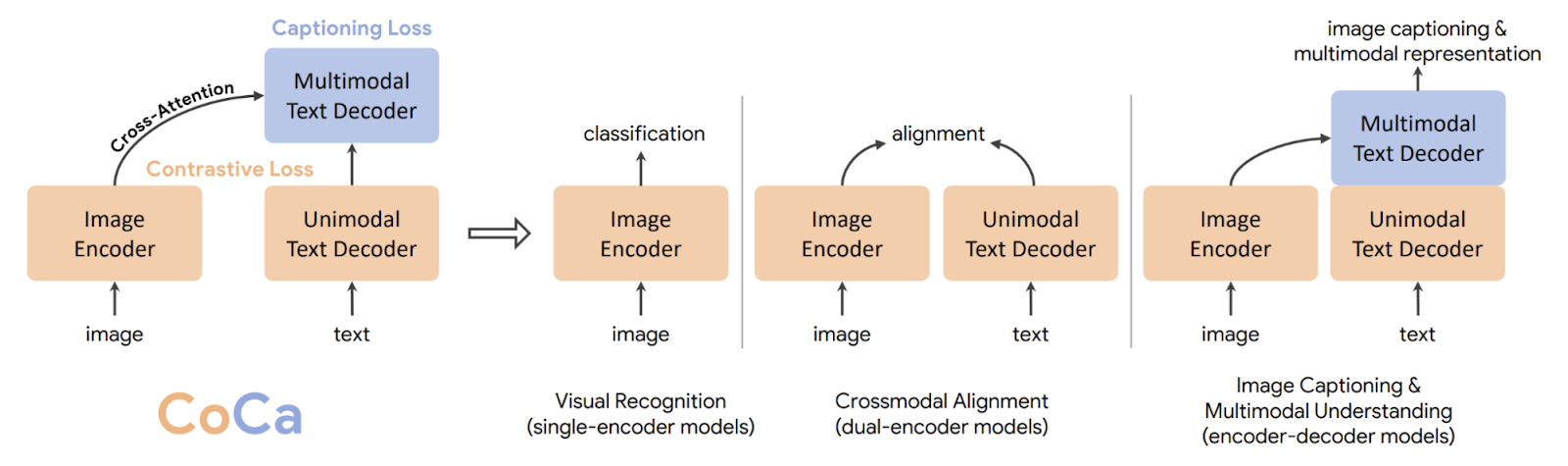
Los investigadores de Google AI presentan un modelo unificado de la columna vertebral de la visión llamado Contrastive Captioner en «CoCa: Contrastive Captioners are Image-Text Foundation Models» (CoCa). El modelo propuesto es una nueva estrategia de decodificador que genera imágenes monomodales consistentes, guiones idénticos y representaciones multimedia compartidas, lo que lo hace lo suficientemente versátil para su uso en una variedad de aplicaciones finales. CoCa, en particular, produce un rendimiento sofisticado en tareas de visión, visión y lenguaje, incluida la identificación de la visión, la alineación intermodal y la comprensión multimodal. También aprende representaciones muy generales, lo que le permite competir o superar modelos que han sido ajustados utilizando codificadores congelados o de aprendizaje sin disparos.
https://ai.googleblog.com/2022/05/image-text-pre-entrenamiento-con.html
método
CoCa es un sistema de entrenamiento unificado que combina de manera efectiva modelos de codificación simple, codificación dual y decodificación al integrar la pérdida de varianza y la pérdida de anotaciones en un solo flujo de datos de entrenamiento que consta de anotaciones de imágenes, pares de imágenes y textos molestos.
Para ello, describen una nueva arquitectura para el codificador y el decodificador. El codificador es un transductor de visión (ViT), y el decodificador de texto se divide en dos partes: un decodificador de texto monomedia y multimedia. Secuencia las capas del decodificador multimedia con atención mutua a la salida del codificador de imágenes para aprender términos de texto multimedia para la pérdida de subtítulos. Este enfoque aumenta la versatilidad y la universalidad del modelo para adaptarse a una amplia variedad de funciones, al tiempo que lo entrena de manera efectiva con solo una extensión hacia adelante y hacia atrás para cada uno de los objetivos de entrenamiento, lo que resulta en un gasto computacional pequeño. Como resultado, el modelo se puede entrenar desde cero a un costo similar al de un modelo de decodificador ingenuo.
Resultados de la evaluación comparativa
Con una adaptación mínima, el modelo CoCa se puede ajustar directamente a diferentes actividades. Su modelo ha obtenido un rendimiento de vanguardia en muchos estándares famosos de visión y multimedia, que incluyen
(1) Reconocimiento visual, Kinetics-400/600/700 y MiT;
(2) alineación de medios cruzados, MS-COCO, Flickr30K y MSR-VTT; Y el
(3) Comprensión multimodal, VQA, SNLI-VE, NLVR2 y NoCaps.
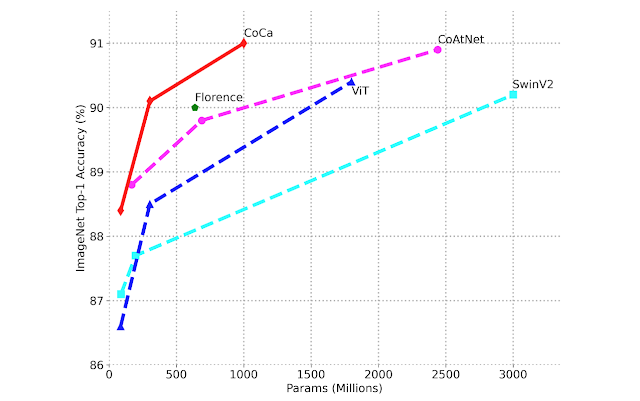
Cabe señalar que CoCa consigue estos resultados como un único modelo adaptado a todas las funciones siendo mucho más ligero que los anteriores modelos especializados de alto rendimiento. CoCa, por ejemplo, logra el 91,0 por ciento de la precisión Top-1 de ImageNet mientras usa solo la mitad de los parámetros de los últimos modelos modernos. Además, CoCa adquiere la capacidad de generar energía para descripciones de imágenes de alta calidad.
CoCa se compara con otros modelos de columna vertebral de imagen (sin modificación específica de tareas) y una variedad de modelos especializados en tareas de última generación.
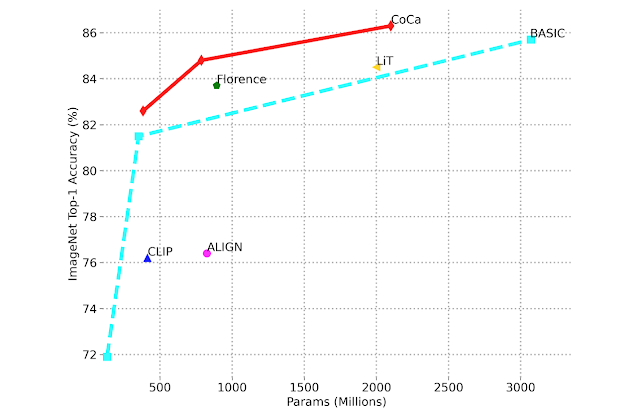
Al comparar el rendimiento de una métrica de clasificación de imágenes ajustada con precisión, la resolución Top-1 de ImageNet frente al tamaño del modelo.
CoCa generó subtítulos de texto usando imágenes NoCaps como entrada.

Rendimiento sin tiro
CoCa supera a los modelos de última generación anteriores en tareas de aprendizaje de base cero, como la clasificación de imágenes y la recuperación multimedia, y logra un rendimiento excepcional con ajustes finos. En ImageNet, CoCa logra una precisión de disparo cero del 86,3 % y supera a los modelos anteriores en estándares de contraste desafiantes como ImageNet-A, ImageNet-R, ImageNet-V2 e ImageNet-Sketch. En comparación con los enfoques anteriores, CoCa logra una mayor precisión de disparo cero en tamaños de modelo más pequeños, como se muestra en la imagen a continuación.
Medición del rendimiento de la clasificación de imágenes en comparación con la precisión de la primera instantánea cero de ImageNet en comparación con el tamaño del modelo.
Representación de codificadores congelados
CoCa proporciona un rendimiento similar al ajuste de los mejores modelos con solo un codificador visual congelado, que utiliza características extraídas después del entrenamiento del modelo para entrenar al clasificador en lugar del esfuerzo computacional más costoso para ajustar el modelo. En ImageNet, el codificador de CoCa inmovilizado con un cabezal de clasificación aprendido logra un 90,6 % más de precisión, superando a los actuales modelos principales finamente ajustados. Este enfoque también funciona muy bien para el reconocimiento de video. Introducen fotogramas de vídeo individuales en un codificador de imágenes congeladas CoCa y utilizan la agregación intencionada para combinar las características de salida antes de aplicar el clasificador adquirido. En el conjunto de datos Kinetics-400, esta solución básica que utiliza el codificador de imágenes congeladas CoCa logra la precisión más alta del 88,0 por ciento, lo que demuestra que CoCa aprende una representación visual muy general con objetivos de capacitación comunes.
Comparación del codificador óptico Frozen CoCa con (muchos) modelos ajustados que ofrecen el mejor rendimiento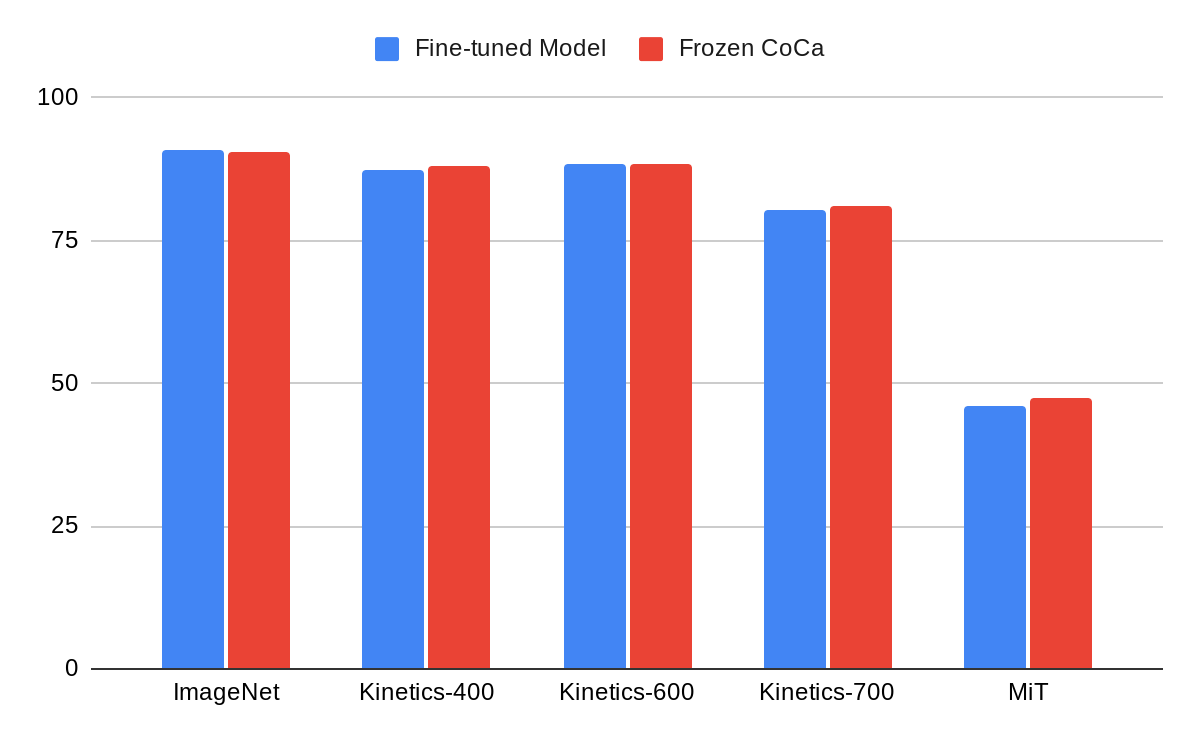
conclusión
Contrast Captioner (CoCa) es un modelo único para el modelo básico de textos de imagen de preentrenamiento. Esta estrategia sencilla se adapta a una amplia gama de problemas posteriores en la visión, la visión y el lenguaje, y produce resultados sofisticados con pocas o ninguna modificación específica de la tarea.
This Article is written as a summay by Marktechpost Staff based on the Research Paper 'CoCa: Contrastive Captioners are Image-Text Foundation Models'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper, and blog. Please Don't Forget To Join Our ML Subreddit

«Experto en Internet. Lector. Fanático de la televisión. Comunicador amistoso. Practicante de alcohol certificado. Aficionado al tocino. Explorador. Malvado adicto a los tweets».
More Stories
Obtenga dos cargadores y cables rápidos Anker USB-C por solo $ 13 con Amazon Prime
Los desarrolladores de «Tarkov» acusan a «Arena Breakout Infinite» de plagio
Qualcomm dice que sus chips Snapdragon X Plus de gama baja aún pueden superar al M3 de Apple